In the semiconductor industry, chips are usually divided into digital chips and analog chips. Among them, digital chips have a relatively large market share, reaching about 70%.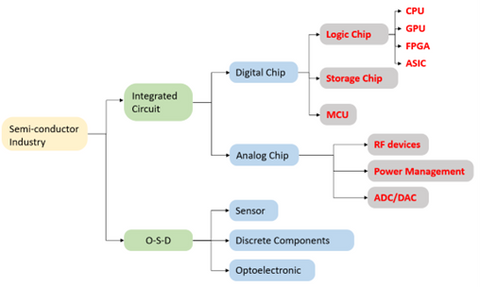
Digital chips can be further divided into logic chips, storage chips, as well as Microcontroller Unit (MCU) storage chips, and MCUs will be introduced later. For Logic chips, to put it simply, are computing chips. They contain various logic gate circuits, which can realize arithmetic and logical functions and are one of the most common types of chips. The CPUs, GPUs, FPGAs, and ASICs that people often hear about all belong to logic chips. And the so-called "AI chips" that are particularly popular now mainly refer to them.
CPU
First, let's talk about the CPU, which stands for Central Processing Unit. Everyone knows that the CPU is the heart of a computer. Modern computers are based on the von Neumann architecture born in the 1940s. In this architecture, it includes an Arithmetic Logic Unit (ALU), Control Unit (CU), memory, input devices, output devices, and other components. When data arrives, it is first placed into memory.
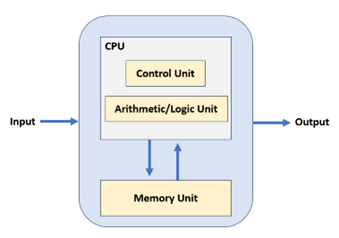
Then, the control unit fetches the corresponding data from memory and hands it over to the ALU for computation. After the computation is completed, the result is returned to memory. This process has a more sophisticated term: "Fetch-Decode-Execute-Memory Access-Write Back
As you can see, the ALU and the control unit, the two core functions, are both handled by the CPU. Specifically, the ALU (including adders, subtractors, multipliers, dividers) is responsible for executing arithmetic and logic operations, doing the real work. The control unit is responsible for fetching instructions from memory, decoding instructions, and executing instructions, it's like the hands and feet of the CPU.
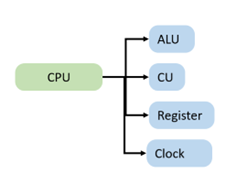
In addition to the ALU and the control unit, the CPU also includes components like the clock module and registers (cache). The clock module manages the time for the CPU, providing a stable time base for it. It drives all operations in the CPU periodically by issuing signals, scheduling the work of each module. Registers are high-speed storage in the CPU used to temporarily store instructions and data. Acting as a "buffer" between the CPU and memory (RAM), its speed is faster than regular memory, avoiding memory "dragging down" the CPU's work.
GPU
Now, let’s move on to Graphics Processing Unit (GPU). In 1999, NVIDIA was the first to propose the concept of the GPU.
The reason for introducing the GPU was the rapid development of gaming and multimedia businesses in the 1990s. These businesses demanded higher 3D graphics processing and rendering capabilities from computers. Traditional CPUs couldn't handle it, so GPUs were introduced to share this workload.
According to their form, GPUs can be divided into discrete GPUs (dGPU) and integrated GPUs (iGPU), also known as dedicated graphics and integrated graphics. The GPU is also a computing chip. So, like the CPU, it includes components such as arithmetic logic units, control units, and registers. However, because the GPU mainly handles graphics processing tasks, its internal architecture is very different from the CPU.
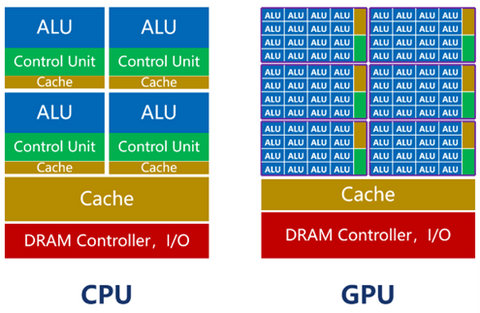
As shown in the above figure, the number of cores in the CPU (including the ALU) is relatively small, with at most only a few dozen. However, the CPU has a large amount of cache and complex controllers. The reason for this design is that the CPU is a general-purpose processor. As the main core of the computer, its tasks are very complex, requiring it to handle different types of data calculations and respond to human-computer interaction.
Complex conditions and branches, as well as synchronization and coordination between tasks, will result in a large number of branch jumps and interrupt processing work. It needs larger caches to store various task states to reduce latency during task switching. It also requires more complex controllers for logical control and scheduling.
The strength of the CPU lies in management and scheduling. The actual workload, on the other hand, is not strong (the ALU accounts for about 5% to 20%). If we consider the processor as a restaurant, the CPU is like a versatile restaurant with dozens of high-level chefs. This restaurant can cook all kinds of cuisines, but because there are many types of dishes, it takes a lot of time to coordinate and prepare them, so the serving speed is relatively slow.
The GPU, on the other hand, is completely different. The GPU is born for graphics processing, with a very clear and single task. What it has to do is graphic rendering. Graphics are composed of a massive number of pixels, which are highly uniform and independent large-scale data types. Therefore, the task of the GPU is to perform parallel computation of a large amount of homogeneous data in the shortest possible time. The so-called "miscellaneous tasks" of scheduling and coordination are relatively rare.
The number of cores in a GPU far exceeds that of a CPU, often reaching several thousand or even tens of thousands (thus earning the moniker "many-core"). The cores in a GPU, referred to as Stream Multi-processors (SM), function as independent task processing units. Within the entire GPU, it is divided into multiple streaming processing regions. Each processing region contains hundreds of cores. Each core, akin to a simplified version of a CPU, possesses functionalities for integer and floating-point operations, as well as queuing and result collection capabilities.
The controller functionality of the GPU is straightforward, and it has relatively fewer caches. Its ALU ratio can exceed 80%. Although the processing capability of a single GPU core is weaker than that of a CPU, its sheer quantity makes it highly suitable for intensive parallel computing. Under equivalent transistor scale conditions, its computational power can even surpass that of a CPU.
For Artificial Intelligence (AI)
Everyone knows that nowadays, AI computing relies heavily on GPUs, and NVIDIA has reaped immense profits as a result. Why is this the case? The reason is quite simple: because AI computing, much like graphic computing, involves a significant amount of high-intensity parallel computing tasks.
Deep learning currently represents the mainstream artificial intelligence algorithm. From a procedural standpoint, it encompasses two main phases: training and inference. During training, a complex neural network model is trained using a large volume of data. During inference, this trained model is employed to derive various conclusions from extensive datasets.
The training phase, due to its involvement with vast training datasets and complex deep neural network structures, demands a massive computational scale and places high requirements on chip computational power. On the other hand, the inference phase requires high efficiency in repetitive calculations and low latency. The specific algorithms utilized, including matrix multiplication, convolution, recurrent layers, gradient operations, etc., are decomposed into numerous parallel tasks, effectively reducing the time required to complete each task.